FAIR is one of those acronyms that spreads rapidly, acquires a life of its own and can mean many things to different groups. A two-day event has just been held in Amsterdam to bring some of those groups from the chemical sciences together to better understand FAIR. Here I note a few items that caught my attention.
- Fairsharing.org was the basis for several presentations. It serves as “a curated, informative and educational resource on data and metadata standards, inter-related to databases and data policies.” It promotes establishing metrics which strive to quantify how FAIR any given resource is.[1] Any site which achieves a good FAIR metric can be described as a FAIR data point (a term new to me), and which can serve as an exemplar of what FAIR data aspires to.
- Intrigued, I offered this page and hope to establish its FAIR metric in the near future, if only to understand how to improve its “score” so that future pages can be improved. It is based on the following Figure[2] which appeared in a recent article and appears to be a publishing “first” in as much as the figure contains hyperlinks directly to the data sources upon which it is based. The putative FAIR data point takes this a little further by wrapping the figure with visualisation tools which take the FAIR data and convert it to interactive models with the help of an added toolbox.
- Another topic for discussion was spectroscopy and a veritable file format for its distribution, JCAMP-DX. One emerging theme is the idea of promoting two types of spectral distribution. The first is the use of a common standard format (JCAMP-DX) which strives to eliminate much of the proprietary character associated with data emerging from instruments. At the other extreme is to to offer to readers the raw instrumental data,[3] which has the advantage of having none of the inevitable loss of information when transforming to standard formats. The downside is that it almost always can only be processed using proprietary software provided by the instrument vendor. One way of avoiding this is Mpublish (the topic of an earlier blog) and we heard interesting updates on progress from MestreLabs, the originators of this procedure. It is still my hope that more vendors (both of instruments and of software) will adopt such a model.
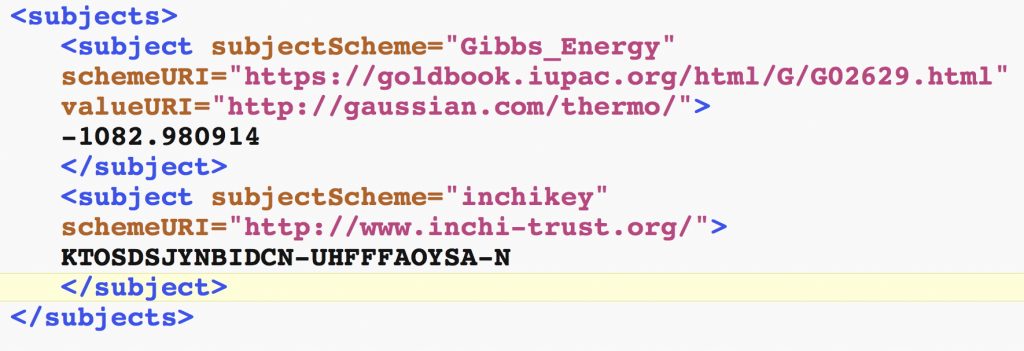
- A further topic was metadata, which is at the heart of each of the terms in FAIR (F = findable, A = accessible, I = interoperable and R = re-usable), which are all defined in part at least by the metadata associated with any item. The state of metadata associated with research data is often dire, and often too little resource has been assigned to its improvement. I presented an example of how richer metadata might be injected. The below is a snippet of the metadata associated with one entry in a data repository (download the metadata here and open the file with a text editor). An advantage of doing this is that rich searches against these terms become enabled.
- Finally, I note events such as e.g. Harnessing FAIR data are starting to spring up. This one is at Queen Mary University of London on 3rd September 2018, for which “PhDs and Post Docs from a range of disciplines” are welcomed, they of course being the pre-eminent generators of data and often the ones in charge of making it “FAIR”.
Author
References
- M.D. Wilkinson, S. Sansone, E. Schultes, P. Doorn, L.O. Bonino da Silva Santos, and M. Dumontier, "A design framework and exemplar metrics for FAIRness", Scientific Data, vol. 5, 2018. https://doi.org/10.1038/sdata.2018.118
- S. Arkhipenko, M.T. Sabatini, A.S. Batsanov, V. Karaluka, T.D. Sheppard, H.S. Rzepa, and A. Whiting, "Mechanistic insights into boron-catalysed direct amidation reactions", Chemical Science, vol. 9, pp. 1058-1072, 2018. https://doi.org/10.1039/c7sc03595k
- J.B. McAlpine, S. Chen, A. Kutateladze, J.B. MacMillan, G. Appendino, A. Barison, M.A. Beniddir, M.W. Biavatti, S. Bluml, A. Boufridi, M.S. Butler, R.J. Capon, Y.H. Choi, D. Coppage, P. Crews, M.T. Crimmins, M. Csete, P. Dewapriya, J.M. Egan, M.J. Garson, G. Genta-Jouve, W.H. Gerwick, H. Gross, M.K. Harper, P. Hermanto, J.M. Hook, L. Hunter, D. Jeannerat, N. Ji, T.A. Johnson, D.G.I. Kingston, H. Koshino, H. Lee, G. Lewin, J. Li, R.G. Linington, M. Liu, K.L. McPhail, T.F. Molinski, B.S. Moore, J. Nam, R.P. Neupane, M. Niemitz, J. Nuzillard, N.H. Oberlies, F.M.M. Ocampos, G. Pan, R.J. Quinn, D.S. Reddy, J. Renault, J. Rivera-Chávez, W. Robien, C.M. Saunders, T.J. Schmidt, C. Seger, B. Shen, C. Steinbeck, H. Stuppner, S. Sturm, O. Taglialatela-Scafati, D.J. Tantillo, R. Verpoorte, B. Wang, C.M. Williams, P.G. Williams, J. Wist, J. Yue, C. Zhang, Z. Xu, C. Simmler, D.C. Lankin, J. Bisson, and G.F. Pauli, "The value of universally available raw NMR data for transparency, reproducibility, and integrity in natural product research", Natural Product Reports, vol. 36, pp. 35-107, 2019. https://doi.org/10.1039/c7np00064b
Tags: Acronym, Amsterdam, chemical sciences, City: Amsterdam, Queen Mary University of London, spectroscopy, Technology/Internet, text editor, University of London, visualisation tools
Re: Item 3 in your list, spectroscopic data.
I am not a spectroscopist nor am I familiar with the file formats in which they are saved and distributed, and this certainly applies to the JCAMP-DX format as well.
However, I have a suggestion derived from audio file formats. Audio files – especially music files – are MUCH more complex than any imaginable spectral recording, and contain a larger volume of data. There exists an audio codec named “.flac” (“Free Lossless Audio Codec”), which is, as its name suggests, lossless. Hence it can recreate exactly the waveforms of the original recording, but in comparison to the original audio track (recorded in, say, a “.wav” or “.aif” codec), the same file encoded in the .flac codec occupies only 20-25% of the storage as compared to the original recording. Furthermore, the .flac format definition is located in the public domain, so the algortihms (and doubtless the actual software) are available at no cost.
One would hope that the various FAIR groups who are investigating storage of spectroscopic data are aware of this alternative.
David,
The issues with raw e.g. NMR data are less to do with its size and more with the complexity of the files. A Bruker NMR fileset for example can comprise up to 32 different files, some binary (i.e. compressed), some text. Several of these files contain settings parochial to the instrument used. They are often organised into hierarchical folders. So the solution adopted is not to try to interfere with this collection, but to ZIP it up into an archive, which is then offered to specialist software for lossless analysis.
The solution you suggest above addresses issues of file sizes and whilst FLAC might be more efficient than ZIP, the files are nevertheless quite small, rarely exceeding 10 Mbytes. It is true that modern pulse experiments record data in parallel, thus effectively collecting data for 5 or more pulse sequences in a single experiment. So it is likely that NMR file sizes are certainly getting larger, but the need for more efficient compression is I think still a little while away.
It might be different for crystal diffraction data. The raw image data here can range from between ~300 Mbyte up to 12-14 Gbyte (on modern instruments with detectors that in effect detect every single photon) and there efficient compression does start to be an issue. The solution however is to in effect analyse the model to remove “empty space” in the diffraction data rather than to compress using a codec. I gather that such analysed image data is very much smaller than the original. Clearly however the (slight?) loss of information resulting is considered acceptable for the analysis of the structure.
Coincident with the Amsterdam meeting (which focused on chemistry) is the release of a JISC (UK funding council) report entitled FAIR in practice (DOI: 10.5281/zenodo.1245567). It is about 85 pages long, with much detail. One immediate overlap with the above is the focus on raw data; “There is a significant volume of data that is not effectively managed, particularly raw or unprocessed data, and the supporting infrastructure is absent“. Thus makes the Mpublish system, first highlighted here on this blog two years ago, even more timely!