I can remember a time when journal articles carried selected data within their body as e.g. Tables, Figures or Experimental procedures, with the rest consigned to a box of paper deposited (for UK journals) at the British library. Then came ESI or electronic supporting information. Most recently, many journals are now including what is called a “Data availability” statement at the end of an article, which often just cites the ESI, but can increasingly point to so-called FAIR data. The latter is especially important in the new AI-age (“FAIR is AI-Ready”). One attribute of FAIR data is that it can be associated with a DOI in addition to that assigned to the article itself, and we have been promoting the inclusion of that Data DOI in the citation list of the article.[1] Since the data can also cite the article, a bidirectional link between data and article is established. ESI itself can exceed 1000 “pages” of a PDF document and examples of chemical FAIR data exceeding 62 Gbytes[2] (Also see DOI: 10.14469/hpc/10386) are known. Finding the chemical needle in that data haystack can become a serious problem. So here I illustrate a recent suggestion for moving to the next stage, namely the inclusion of a “Data Availability and Discovery” statement. The below is the text of such a statement in a recently published article.[3]
Data availability and discovery statement. Available as a FAIR and AI-ready data collection accessible via doi: 10.14469/hpc/13058 for the overall collection18 and Findable by following the hierarchy of data collections identified there. The data discovery and accessibility aspects are further enabled by using one of the following methods.
- Discovery using a metadata search query. A example template for identifying kinetic isotope data deriving from a Gaussian calculation is here provided as: https://commons.datacite.org/?query=media.media_type:chemical/x-gaussian-log+AND+media.media_type:text/plain+AND+(titles.title:*Exo*+OR+titles.title:*Endo*) This query can be modified or extended as required.
- Discovery using an enhancement of Table 1,55 doi: 10.14469/hpc/13370 acting as a data Finding Aid via links to data collections associated with each row of Table 1. A visual tool for displaying interactive 3D coordinate models illustrating the transition structure normal vibrational modes is interactively created by re-using data accessed and exploiting information in the metadata record associated with the FAIR doi of each dataset.
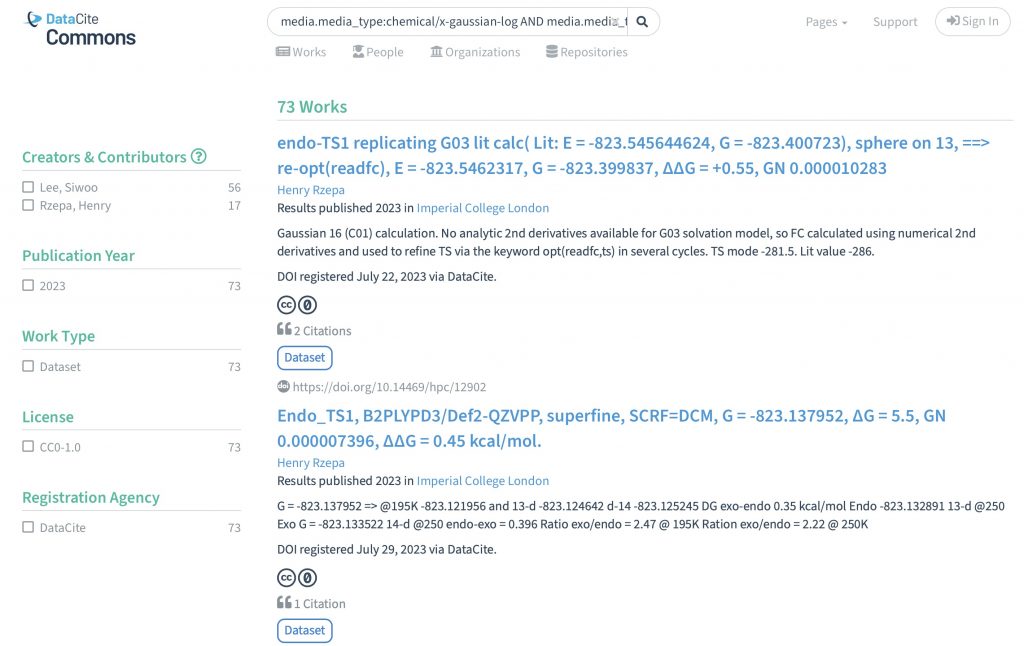
Many variations on the above search can be constructed[4] It is also useful to note that the above syntax presents the results of the search in “human readable” form. For a machine version, either of the two forms below should be used.
- https://api.datacite.org/dois/?query=media.media_type:chemical/x-gaussian-log+AND+media.media_type:text/plain+AND+(titles.title:*Exo*+OR+titles.title:*Endo*)
- curl "https://api.datacite.org/dois/?query=media.media_type:chemical/x-gaussian-log+AND+media.media_type:text/plain+AND+(titles.title:*Exo*+OR+titles.title:*Endo*)"
These last forms emphasise that data discovery is aimed at machine automation as well as humans.
Finally, I ponder how machines will respond to articles containing references to such discoverability. Ideally, the machine actionable information should itself be included in the (CrossRef) metadata describing the article. At the moment that aspect is perhaps the weakest point of machine discoverability associated with journals.
Author
References
- H. Rzepa, "The journey from Journal "ESI" to FAIR data objects: An eighteen year old (continuing) experiment.", 2023. https://doi.org/10.59350/g2p77-78m14
- T. Mies, A.J.P. White, H.S. Rzepa, L. Barluzzi, M. Devgan, R.A. Layfield, and A.G.M. Barrett, "Syntheses and Characterization of Main Group, Transition Metal, Lanthanide, and Actinide Complexes of Bidentate Acylpyrazolone Ligands", Inorganic Chemistry, vol. 62, pp. 13253-13276, 2023. https://doi.org/10.1021/acs.inorgchem.3c01506
- D.C. Braddock, S. Lee, and H.S. Rzepa, "Modelling kinetic isotope effects for Swern oxidation using DFT-based transition state theory", Digital Discovery, vol. 3, pp. 1496-1508, 2024. https://doi.org/10.1039/d3dd00246b
- H. Rzepa, "A cascading tutorial in finding rich NMR data using the Datacite datasearch engine.", 2020. https://doi.org/10.59350/7jq8v-z4p56
[…] be able to depart a reaction, or trackback from your individual website […]