I remember a time when tracking down a particular property of a specified molecule was an all day effort, spent in the central library (or further afield). Then came the likes of STN Online (~1980) and later Beilstein. But only if your institution had a subscription. Let me then cut to the chase: consider this URL: http://search.datacite.org/ui?q=InChIKey%3DLQPOSWKBQVCBKS-PGMHMLKASA-N The site is datacite, which collects metadata about cited data! Most of that data is open in the sense that it can be retrieved without a subscription (but see here that it is not always made easy to do so). So, the above is a search for cited data which contains the InChIkey LQPOSWKBQVCBKS-PGMHMLKASA-N. This produces the result:
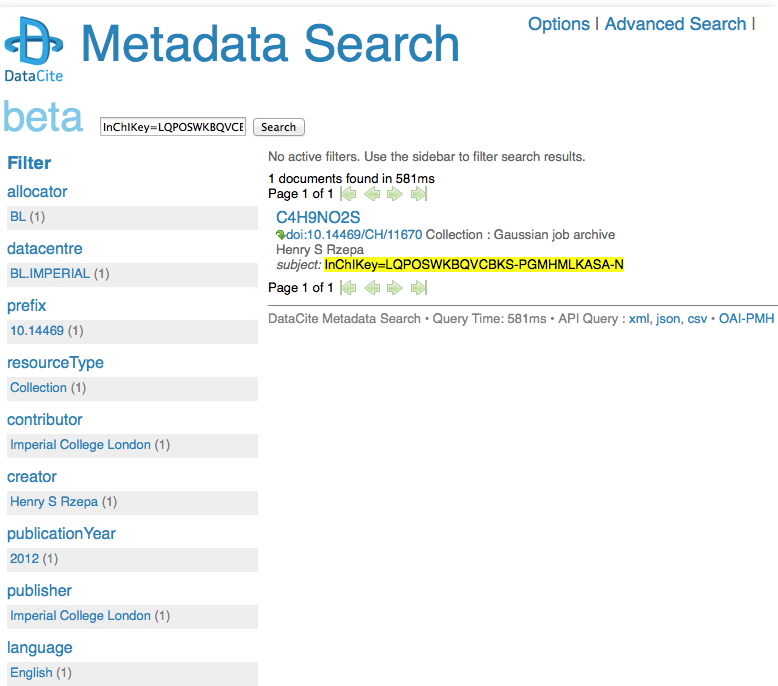
This tells you who published the data (but oddly, its date is merely to the nearest year? It is beta software after all). The advanced equivalent of this search looks like this:
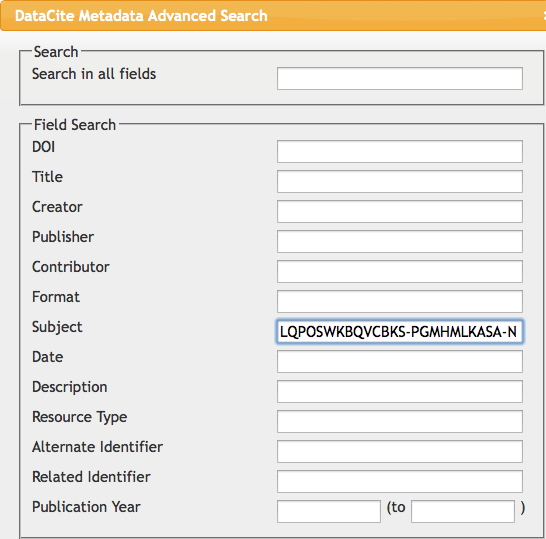
where the subject of the search is now the InChIkey. If you are familiar with the various molecular search engines, you will appreciate that this generic data search is still fairly primitive. But SEO (search engine optimisation) achieved by improving the quality of the metadata would help improve that experience.
The important thing about DataCite is that it only searches the metacontent of digital repositories, wherein one may expect to find properly curated data, and in particular the possibility of not merely finding highly processed data, but also of the original (instrumental or computational) datafile from which the metadata was abstracted. Rather than a visual graph, one might expect to also find the original data (to however many decimal points). Rather than just molecular coordinates, one might also find a full wavefunction describing the electron density distribution, or a full spectral analysis. In the original form as deposited by researchers, and not in a processed form as supplied by an “added value” resource. Don’t get me wrong; validated data is wonderful, but validation has to be done according to a schema, and such schemas change, improve, evolve over time.
The other important point I think which the above introduces is the concept that DataCite (and similar organisations) might act as a portal, through which software agents might act to validate/aggregate data. The utopian world would be that every organisation that produces data captures it in a form that DataCite and others can find. Unless of course the data is in itself also their business model, and they wish to exert a monopoly over it. One might appreciate monopolies if the alternative is not having access to the data at all, but perhaps at the expense of innovation? I cannot help but feel that once data citation as shown above becomes a generally accepted best practice amongst scientists, then entirely new ways of adding value to it will emerge in abundance. It would be interesting to see whether the current more monopolistic models survive this transition by upping their own game.
Author
Tags: beta software, generic data search, molecular search engines, search engine, search engine optimisation, search looks, software agents