It is a sign of the times that one travels to a conference well-connected. By which I mean email is on a constant drip-feed, with venue organisers ensuring each delegate receives their WiFi password even before their room key. So whilst I was at a conference espousing the benefits of open science, a nice example of open collaboration was initiated as a result of a received email.‡
Steven Kirk ![]() contacted me with the following query: Do you know of any open-access database of calculated IRCs with coverage of as broad a range of classes of chemical reactions as possible? I recollected that about six years ago, I was exploring the use of iTunesU as a system for delivering course content in a rich-media format. I produced animations for about 115 reactions (many of which as it happens were taken from this blog, but quite a number were also unique to that project) and placed them into iTunesU, and now sending the URL https://itunes.apple.com/gb/course/id562191342 to Steven.
contacted me with the following query: Do you know of any open-access database of calculated IRCs with coverage of as broad a range of classes of chemical reactions as possible? I recollected that about six years ago, I was exploring the use of iTunesU as a system for delivering course content in a rich-media format. I produced animations for about 115 reactions (many of which as it happens were taken from this blog, but quite a number were also unique to that project) and placed them into iTunesU, and now sending the URL https://itunes.apple.com/gb/course/id562191342 to Steven.
I should at this point explain something of the structure of such an iTunesU course.
- An essential feature is the course icon, seen below on the left. Since the course is hosted by Imperial College, it had to be an officially approved icon. I am sure you can believe me if I tell you that this took a month or so to obtain, with a fair bit of persistence required!
- I also had to get approval to place the iTunes app on all the teaching computers so that students could open the course. Believe me again when I tell you that I had to persuade the Apple lawyers in Cupertino to release a special license for this app to persuade our administrators here to install it on the Windows teaching clusters. Another few months had passed by.
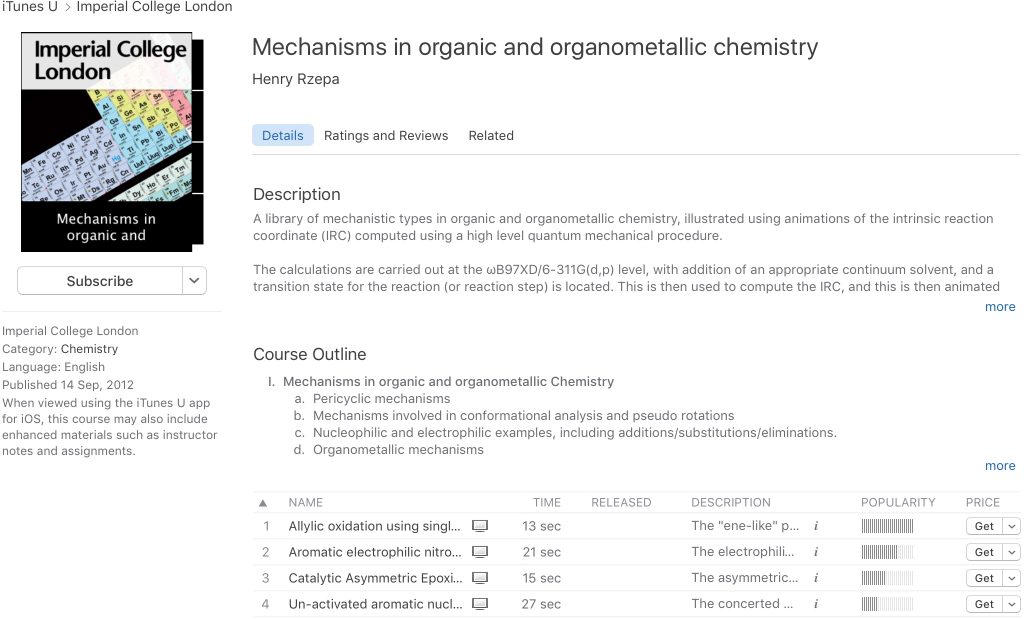
- When creating an entry (using e.g. https://itunesu.itunes.apple.com/coursemanager/ ) one has to specify values for various descriptors, also often called metadata. Thus any one entry has fields for name and description, with the popularity added by Apple. Only a few words are visible in the description field, which can be expanded in iTunes using the i button.

- Steven meanwhile had replied asking if the original data that was used to generate the IRC might be available. Specifically his second question was “So the DOIs are only stamped into the animation’s bitmaps, or are they also somewhere in the metadata?“. That little i button is not easy to spot, and there is no indication, in the event, of what information it might actually contain.
- Here it is expanded. The contents are unstructured text, into which I have placed the required DOI.
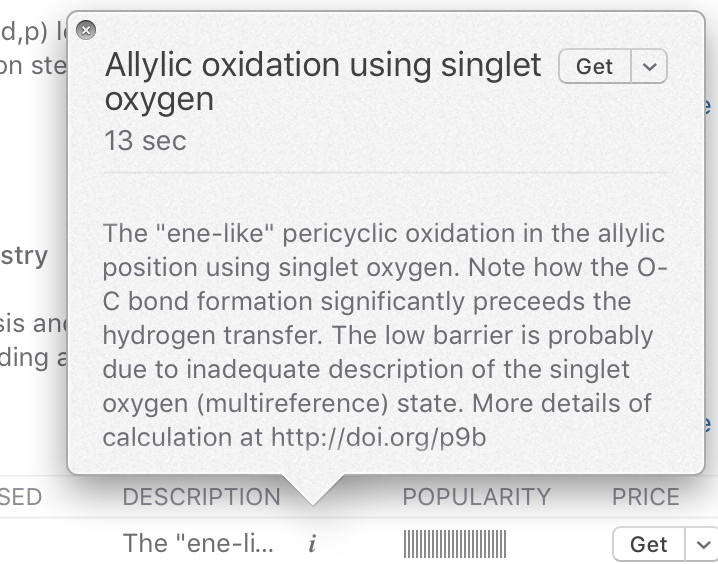
- The lesson here is that I had fortunately had the foresight to include a link to the IRC data in anticipation of just such a question from someone in the future. But black mark to Apple here; the text cannot be selected and copied into a clipboard! It is fairly unFAIR data, since it can only be inter-operated (the I of FAIR) by a human re-typing it by hand. And the human has also to recognise the pattern of a DOI; a machine could not obtain this information easily. Moreover Steven is a Linux user; he does not readily have access to the iTunes app on this operating system!
- Also, there were 115 such entries, and now the prospect was rearing that each would have to be hand processed. Moreover, because the text was unstructured, there was no guarantee that I would have adopted the same pattern for all 115 entries.
- Fortunately Steven was on the ball. I quote again: it turns out iTunes isn’t needed at all. A service I found on the web http://picklemonkey.net/feedflipper-home/ takes an ITunes URL and converts it to an RSS feed. Opening this feed in Firefox and RSSOwl respectively let me save the feed as XML and HTML (both attached).
- This is currently where we stand (Steven’s first email was two days ago), but it’s not finished yet. Depending on how assiduous I was five years ago, some DOIs to the data may be acquired from the list. Sometimes I simply wrote e.g. See http://www.ch.imperial.ac.uk/rzepa/blog/?p=6816 knowing that the links to the data were there instead. I can already see that some descriptions have neither a DOI nor a link to the blog. More detective work will be needed, unfortunately.
How might the situation described above been avoided? Well, Apple in iTunesU only provided in effect one metadata field, and this was an unstructured one. Anything went in that field. Had they provided (or had the course creator been able to configure it themselves) there might have been another field entitled say “data source“. This could moreover been made a mandatory field and a structured one. Thus it might have only accepted known types of persistent identifier, such as a DOI. Further, the system could have checked that the DOI was actually resolvable. Before you ask, I did log a “bug” with Apple asking this be done, but nothing ever was. With such a tool to hand, I might have achieved data sources for all the 115 entries. The resulting XML (as generated above) could have been used to automate the retrieval of all 115 datasets describing this course.
At this stage then, Steven can follow-up his interest in building a reaction IRC library and analysing it. I will do all I can to encourage Steven not to make the mistakes I did and to ensure that any further data that is required to augment the library does not suffer the problems above. On the other hand, I console myself that in two days, much of the data for the course I created five years ago was salvageable; I wonder how many other iTunesU courses there are for which that can be said!
I will let (with some blushing) the final word be Steven’s: You are one of the few chemists who has both pioneered and built the principles of ‘open chemistry’ into their actual scientific work. I visit your blog occasionally knowing that there is a very high probability I could download and tinker with the results of real calculations.
‡Might I assure all the speakers that I concentrated totally on their talks rather than incoming emails!
Author
Tags: animation, chemical reactions, City: Cupertino, Company: Cupertino Elec, Company: Firefox Communic, Computer Hardware - NEC, computing, detective, Digital media, Drip, Electronic documents, Electronic publishing, Email, HTML, Imperial College, Linux, operating system, Password, Person Location, Steven Kirk, Technology/Internet, XML