In an era when alternative facts and fake news afflict us, the provenance of scientific data becomes ever more important. Especially if that data is available as open access and exploitable by others for both valid scientific reasons but potentially also by those with other motives. Here I consider the audit trail that might serve to establish data provenance in one typical situation in chemistry, the acquisition of NMR instrumental data.
Here I describe how such data is generated in my department; details may vary elsewhere.
- The prospective user of the NMR service is allocated a service ID. In our case, that ID relates to the research group rather than to individual researchers. This ID is parochial, it does not reference any other information about the user in the institute. Only the service manager has the information to associate this ID with real users and this information is normally not distributed.
- When a sample is submitted, this ID is used to create a new folder containing the data as a sub-folder of the group ID and located on the NMR data servers.
- The dataset itself‡ contains a number of files that contain an audit trail (names such as audita.txt, auditp.txt) with the fields: ##AUDIT TRAIL= $$ (NUMBER, WHEN, WHO, WHERE, PROCESS, VERSION, WHAT). Typically, none of these files have propagated the original user ID under which the data was collected; to do so would require a programmatic connection between the local authentication systems and the spectrometer software used, a connection that is normally missing. Thus the first break in the provenance trail.
- In principle other audit trails can be inferred from these files, such as the unique identity of the instrument provided by its manufacturer. Further information such as e.g. the probe used to collect the data (probes can be readily changed over) or any calibration data used in setting up the instrument for the data collection are by and large not recorded. To my knowledge, although an instrument can have a unique serial number, such serial numbers of swappable components such as probes are not recorded by the collection software. Thus the second break in the provenance trail.
- This data then needs to be processed by further software. In this case we use the MestreNova system for this task. Each dataset has editable assigned properties; below I show those that can be associated with the spectrum (accessed with MestreNova using Edit/Properties). All this comes from the information collected by the instrument. The user’s identity can be inserted into the “title” field, the display of which is off by default.
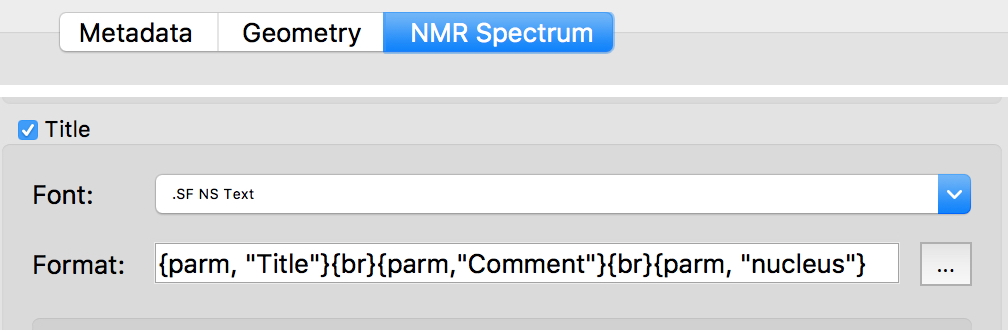
- There is also a section for parameters, a synonym for which might be metadata and accessed using this program from View/Tables/Parameters. If Author was entered as a parameter in the dataset by the spectrometer software, the Mnova document would retrieve that information. Equally, an ORCID identifier for the author entered at the time of data collection and thus stored in the dataset could be read by Mnova, stored and displayed if configured to do so. It would be fair to say however that this option is rarely if indeed ever systematically implemented by NMR instrument data collection software and so is never propagated to the data processing software (as highlighted in red below). Thus a third break in the provenance trail.
 This is also an alternative and this time formal metadata field that can be populated, by default as shown below with the type of spectrum and nucleus. These properties are not controlled in the sense of only allowing those terms that are present in a specified dictionary. The jargon for such control is a metadata schema. This is not used here, since dissemination of this information is not intended; the software accepts whatever information it is given.
This is also an alternative and this time formal metadata field that can be populated, by default as shown below with the type of spectrum and nucleus. These properties are not controlled in the sense of only allowing those terms that are present in a specified dictionary. The jargon for such control is a metadata schema. This is not used here, since dissemination of this information is not intended; the software accepts whatever information it is given.
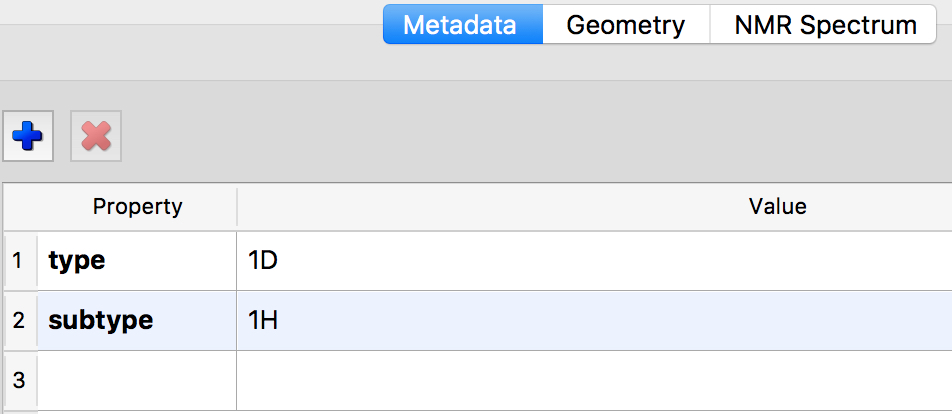 There are thus several opportunities to collect the identity of the experimenter and thus attribute provenance to the collected data, but this does very much depend on the will of researchers, institutions or publishers to enforce specific policies around this. The fourth break in the provenance trail.
There are thus several opportunities to collect the identity of the experimenter and thus attribute provenance to the collected data, but this does very much depend on the will of researchers, institutions or publishers to enforce specific policies around this. The fourth break in the provenance trail. - The dataset can then be uploaded (DOI: 10.14469/hpc/1291), at which stage provenance can finally be added using the ORCID credentials of the person publishing the dataset, who of course may or may not be the person who actually recorded the data! The full metadata for this specific collection can be seen at data.datacite.org/10.14469/hpc/1291. Or to put it another way, this is the first point in the provenance chain where the metadata is controlled by a schema and is also discoverable in a standard programmatic manner, i.e. the preceding link. The provenance is now formally associated with the ORCID identifier using the DataCite metadata schema. You should be aware that a local policy† is that access to the repository at https://data.hpc.imperial.ac.uk is only allowed by cross-authentication with http://orcid.org/ using the user’s ORCID. This identifier is then automatically propagated to the metadata held at e.g. data.datacite.org/10.14469/hpc/1095. Currently however, none of any metadata originally recorded in either the instrumental file set or the processed MestreNova file is forwarded on to the metadata record held at DataCite; again loss of information and potentially of provenance.
- The peer-reviewed article resulting from the interpretation of this data however can be associated with the provenance introduced in the previous stage; see data.datacite.org/10.14469/hpc/1267 and the IsReferencedBy property.
Now imagine if there was a common thread in all the stages of acquiring, processing and publishing this scientific data based on the ORCID.
- Providing an ORCID could be made an essential requirement of access to the instrument.
- This information would be propagated to the dataset …
- by inclusion in one or more of the audit trail files.
- At this stage, further persistent identifiers associated with the instrument manufacturer could be added, which help identify not only the instrument used, but sub-components such as the changeable probe. This would allow access to any calibration curves or probe sensitivity and other aspects.
- The ORCID and other relevant information could be picked up by the software used to convert the data into spectra and propagated into the metadata containers for this software …
- where its use is controlled by a specified schema.
- At this stage, the ORCID and information such as the nucleus recorded, the sample temperature etc can be propagated on to the final metadata records.
- And the reader of the article describing this work would have a formally defined provenance audit trail they could follow back to the start of the experiment or forward to a published article. In this case, the data claims provenance (acquired from peer review) from the article, but it should also work in reverse with the article claiming provenance from the data on which it is based. The indexing of this bidirectional exchange is one of the exciting features that we should see emerging from CrossRef (holders of metadata about articles) and DataCite (holders of metadata about research data) in the near future.
We are clearly a little way from having the infrastructures described above for establishing such data audit trails. To do so will require cooperation from instrument manufacturers, at least in the example as charted above, as well as researchers, institutions, publishers, peer-reviewers and funding bodies. The first step would be to ensure that all scientists who intend collecting, processing and publishing data should claim an ORCID. That remark is directed specifically at undergraduate, postgraduate and post-doctoral researchers, not just at their supervisor or their PI (principal investigator). At a point when the discussion about alternate facts and perhaps even alternate data risks a general loss of confidence in science, we should be pro-active in establishing trust in the scientific processes.
‡ You can see an example obtained by this process at DOI: 10.14469/hpc/1095
† This requirement is a strong driver for the uptake of ORCID amongst our student population.
Author
Tags: Acquisition, Archival science, author, collection software, Company: NMR, data, Data management, data processing software, Evidence law, instrument data collection software, local authentication systems, Mestrenova, MestreNova system, Nuclear magnetic resonance, principal investigator, Provenance, Scientific method, service manager, spectrometer software, supervisor, Technology/Internet, Terminology
Actually the concept a unique ID for researchers would be quite useful. It would allow data and project contributions to be bookmarked as well as demonstrate accountability in accusations of fraud. Rather than a metadata footnote or assignment to a nebulous group identity that changes overtime.
Having every spectra you have taken traceable to you is probably the utmost in provenance
I have received a comprehensive reply from the instrument manufacturer. Here I correct two aspects to put the record straight.
1. The audita.txt file contains the IconNMR user ID that was used to acquire the data. In the example that I quoted, that is ICON-NMR User ID: jh (which does not fully and unambiguously identify the user in this instance).
2. The probehead ID (unique part and serial number) is stored in the acquisition status parameter file acqus: ##$PROBHD= <5 mm PABBO BB/19F-1H/D Z-GRD Z108618/0621>
I also received the encouraging comment So I think in principle we are not in such a bad place, but much or all of the metadata that is associated with the spectra as acquired is not propagated when saving the data within other processing or analysis software.