The Amsterdam manifesto espouses the principles of citable open data. It is a short document, and it is worth re-stating its eight points here:
- Data should be considered citable products of research.
- Such data should be held in persistent public repositories.
- If a publication is based on data not included with the article, those data should be cited in the publication.
- A data citation in a publication should resemble a bibliographic citation and be located in the publication’s reference list.
- Such a data citation should include a unique persistent identifier (a DataCite DOI recommended, or other persistent identifiers already in use within the community).
- The identifier should resolve to a page that either provides direct access to the data or information concerning its accessibility. Ideally, that landing page should be machine-actionable to promote interoperability of the data.
- If the data are available in different versions, the identifier should provide a method to access the previous or related versions.
- Data citation should facilitate attribution of credit to all contributors.
The manifesto itself is dated 20 March 2013, but the principles above go back far earlier, and most of the articles above have been implemented in this blog for a little while now. But its best illustrated with an example[1]. Here I have used the excellent wordpress extension Kcite to adhere to points 1-5 and 8 above. Point 6 is the most interesting perhaps, and it is illustrated below. If you click on the graphic, it will load the log file associated with the calculation described in the previous post to convert the data to a rotatable 3D model, using Jmol.
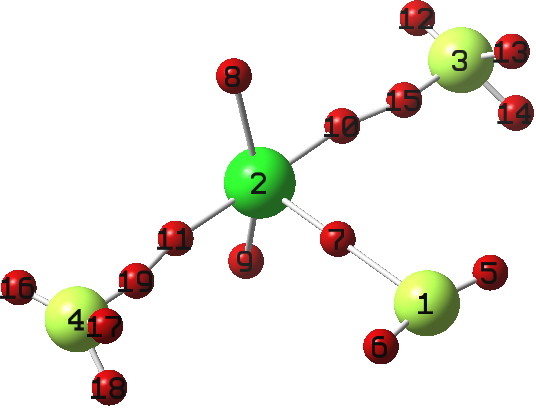
Click to load from Figshare
This actually represents a departure from how I normally invoke data on this blog. I have hitherto done it by uploading the data to the WordPress uploads directory (it is thus in effect a local copy of the data). Here in this post I have not done that; it’s coming directly from the citable data repository, using e.g.
onclick="jmolInitialize('../Jmol/',true);jmolSetAppletColor('white');jmolApplet([450,450],'load http://files.figshare.com/1134372/logfile.log;frame 27;vectors on;vectors 4;vectors scale 5.0; color vectors orange; vibration 10;animation mode loop;');"
Well, almost. The URL of the actual dataset (http://files.figshare.com/1134372/logfile.log) is derived from the doi (10.6084/m9.figshare.757728) by an internal process which has no exposed algorithm. As it happens, the DSpace digital repository[2] is a bit better in this regard.
Click to load from DSpace
This is loaded using
https://spectradspace.lib.imperial.ac.uk:8443/dspace/bitstream/handle/10042/24916/logfile.log;
which is directly derived from the handle itself (although again that algorithm has to be worked out by a human).
Point 7 above is also implemented (sort of). If you look at the Figshare repository, you will notice an additional link there which points to the Dspace repository. As it happens, the two datasets are identical (they are not different versions) and these semantics are currently NOT handled well. You could probably work this out from the date stamps of the two depositions (which are respectively Published on 29 Jul 2013 – 05:58 (GMT) and 2013-07-29T05:58:11Z for Figshare and DSpace respectively).
Whereas the Amsterdam manifesto is here implemented on a blog post, I think the grander aspiration is that the principles are to be followed in ALL scientific publications. We are some way away yet from achieving this. But watch this space for an upcoming example!
So can I urge all scientists who care about data to promulgate the principles of the Amsterdam manifesto, and wherever possible to practice what they preach!
Author
References
- H.S. Rzepa, "Gaussian Job Archive for ClF3", 2013. https://doi.org/10.6084/m9.figshare.757728
Tags: Amsterdam, exposed algorithm, opendata, rotatable 3D model, using Jmol
[…] Chemistry with a twist « The Amsterdam Manifesto on Data Citation Principles […]
[…] distinct component, the “data“. This data would follow the principles of the Amsterdam Manifesto; it would itself be citable. The two components would become symbiotes (a datument). The […]
https://ojs.uv.es/
The Amsterdam Manifesto on Data Citation Principles | Henry Rzepa's Blog