Posts Tagged ‘Information’
Thursday, April 18th, 2019
In a previous post, I looked at the Findability of FAIR data in common chemistry journals. Here I move on to the next letter, the A = Accessible.
(more…)
Tags:Academic publishing, automatic processing, Data management, Digital Object Identifier, EIDR, FAIR data, Findability, Identifiers, Information, Information architecture, Information science, Knowledge, Knowledge representation, metadata, mining, Open Archives Initiative, RDF, Records management, representative, standardized communication protocol, Technical communication, Technology/Internet, Web design, Written communication, XML
Posted in Chemical IT | No Comments »
Friday, April 12th, 2019
In recent years, findable data has become ever more important (the F in FAIR). Here I test that F using the DataCite search service.
(more…)
Tags:Academic publishing, DataCite, Digital Object Identifier, Digital technology, Elsevier, Findability, Identifiers, Information, Information architecture, Information science, Knowledge, Knowledge representation, search service, Web design
Posted in Chemical IT | 1 Comment »
Monday, April 8th, 2019
The conventional procedures for reporting analysis or new results in science is to compose an “article”, augment that perhaps with “supporting information” or “SI”, submit to a journal which undertakes peer review, with revision as necessary for acceptance and finally publication. If errors in the original are later identified, a separate corrigendum can be submitted to the same journal, although this is relatively rare. Any new information which appears post-publication is then considered for a new article, and the cycle continues. Here I consider the possibilities for variations in this sequence of events.
(more…)
Tags:Academic publishing, American Chemical Society, author, Business intelligence, Company: DataCite, CrossRef, data, Data management, DataCite, editor, EIDR, Information, Information science, JSON, Knowledge representation, Metadata repository, Records management, Technology/Internet, The Metadata Company
Posted in Chemical IT | No Comments »
Saturday, February 16th, 2019
The title of this post comes from the site www.crossref.org/members/prep/ Here you can explore how your favourite publisher of scientific articles exposes metadata for their journal.
(more…)
Tags:Aaron Swartz, Academic publishing, API, Business intelligence, CrossRef, data, Data management, Elsevier, favourite publisher, Identifiers, Information, Information science, Knowledge, Knowledge representation, metadata, mining, ORCiD, PDF, Pre-exposure prophylaxis, Publishing, Publishing Requirements for Industry Standard Metadata, Records management, Research Object, Scholarly communication, Scientific literature, search engine, social media, Technical communication, Technology/Internet, text mining, Written communication, XML
Posted in Interesting chemistry | 1 Comment »
Saturday, December 29th, 2018
The traditional structure of the research article has been honed and perfected for over 350 years by its custodians, the publishers of scientific journals. Nowadays, for some journals at least, it might be viewed as much as a profit centre as the perfected mechanism for scientific communication. Here I take a look at the components of such articles to try to envisage its future, with the focus on molecules and chemistry.
(more…)
Tags:Academic publishing, Acrobat, Articles, chemical discoveries, data, Data management, ELN, Information, Molecules, Narrative, PDF, Publishing, Research, Scholarly communication, Science, Scientific Journal, Scientific method, Technical communication, Technology/Internet, Web browser
Posted in Chemical IT | No Comments »
Tuesday, August 7th, 2018
Harnessing FAIR data is an event being held in London on September 3rd; no doubt all the speakers will espouse its virtues and speculate about how to realize its potential.♥ Admirable aspirations indeed. Capturing hearts and minds also needs lots of real life applications! Whilst assembling a forthcoming post on this blog, I realized I might have one nice application which also pushes the envelope a bit further, in a manner that I describe below.
(more…)
Tags:Academic publishing, chemical context, Code, data, DataCite, energy, free energy activation barrier, Identifiers, Information, ISO/IEC 11179, ORCiD, quantum chemical calculations, real life applications, Technical communication
Posted in Interesting chemistry | 9 Comments »
Sunday, May 6th, 2018
The site fairsharing.org is a repository of information about FAIR (Findable, Accessible, Interoperable and Reusable) objects such as research data.
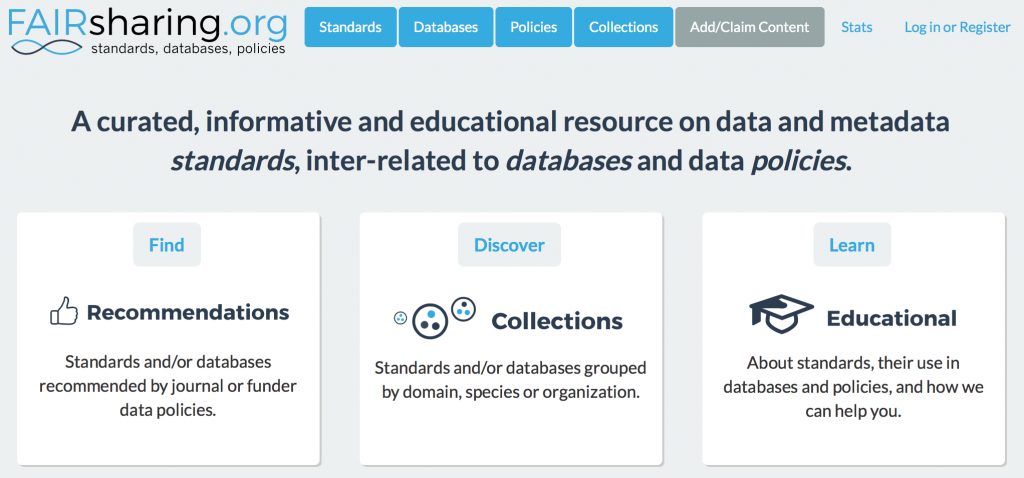
(more…)
Tags:above site, chemical components, Findability, Human behavior, Information, Information architecture, Information science, Institutional repository, journal data editor, Knowledge, Knowledge representation, Open access, Open access in Australia, Oscar, PDF, recognition software, Technology/Internet, Web design
Posted in Interesting chemistry | 2 Comments »
Thursday, December 7th, 2017
FAIR data is increasingly accepted as a description of what research data should aspire to; Findable, Accessible, Inter-operable and Re-usable, with Context added by rich metadata (and also that it should be Open). But there are two sides to data, one of which is the raw data emerging from say an instrument or software simulations and the other in which some kind of model is applied to produce semi- or even fully processed/interpreted data. Here I illustrate a new example of how both kinds of data can be made to co-exist.
(more…)
Tags:computing, Context, data, Data management, Information, Knowledge, Raw data, software simulations, Technology/Internet
Posted in Chemical IT, crystal_structure_mining | No Comments »
Tuesday, November 14th, 2017
PIDapalooza is a new forum concerned with discussing all things persistent, hence PID. You might wonder what possible interest a chemist might have in such an apparently arcane subject, but think of it in terms of how to find the proverbial needle in a haystack in a time when needles might look all very similar. Even needles need descriptions, they are not all alike and PIDs are a way of providing high quality information (metadata) about a digital object.
(more…)
Tags:chemist, computing, Information, Information science, Knowledge representation, librarian, Needle, PID
Posted in Chemical IT | No Comments »