The traditional structure of the research article has been honed and perfected for over 350 years by its custodians, the publishers of scientific journals. Nowadays, for some journals at least, it might be viewed as much as a profit centre as the perfected mechanism for scientific communication. Here I take a look at the components of such articles to try to envisage its future, with the focus on molecules and chemistry.
Posts Tagged ‘Acrobat’
Data nightmares: B40 and counting its π-electrons
Saturday, July 19th, 2014Whilst clusters of carbon atoms are well-known, my eye was caught by a recent article describing the detection of a cluster of boron atoms, B40 to be specific.[1] My interest was in how the σ and π-electrons were partitioned. In a C40, one can reliably predict that each carbon would contribute precisely one π-electron. But boron, being more electropositive, does not always play like that. Having one electron less per atom, one might imagine that a fullerene-like boron cluster would have no π-electrons. But the element has a propensity[2] to promote its σ-electrons into the π-manifold, leaving a σ-hole. So how many π-electrons does B40 have? These sorts of clusters are difficult to build using regular structure editors, and so coordinates are essential. The starting point for a set of coordinates with which to compute a wavefunction was the supporting information. Here is the relevant page: 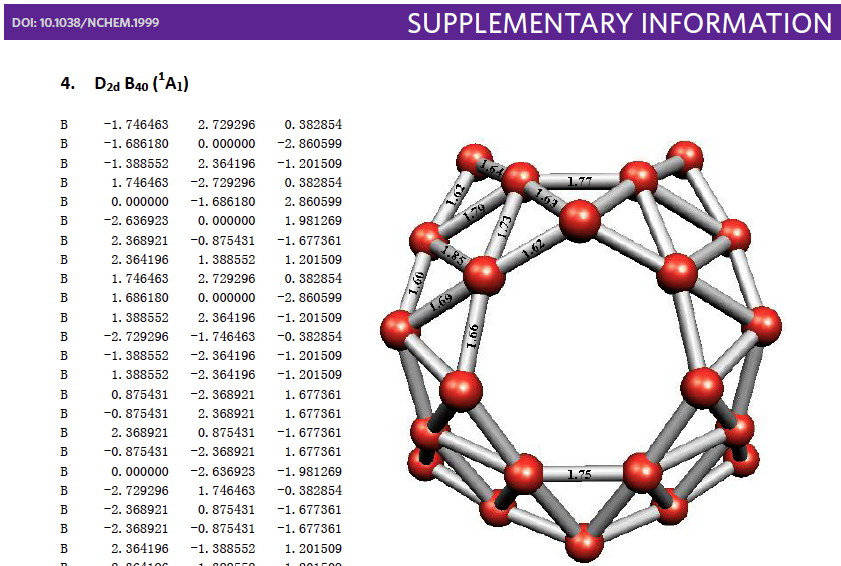 The coordinates are certainly there (that is not always the case), but you have to know a few tricks to make them usable.
The coordinates are certainly there (that is not always the case), but you have to know a few tricks to make them usable.
References
- H. Zhai, Y. Zhao, W. Li, Q. Chen, H. Bai, H. Hu, Z.A. Piazza, W. Tian, H. Lu, Y. Wu, Y. Mu, G. Wei, Z. Liu, J. Li, S. Li, and L. Wang, "Observation of an all-boron fullerene", Nature Chemistry, vol. 6, pp. 727-731, 2014. https://doi.org/10.1038/nchem.1999
- H.S. Rzepa, "The distortivity of π-electrons in conjugated boron rings", Physical Chemistry Chemical Physics, vol. 11, pp. 10042, 2009. https://doi.org/10.1039/b911817a
Science publishers (and authors) please take note.
Monday, October 24th, 2011I have for perhaps the last 25 years been urging publishers to recognise how science publishing could and should change. My latest thoughts are published in an article entitled “The past, present and future of Scientific discourse” (DOI: 10.1186/1758-2946-3-46). Here I take two articles, one published 58 years ago and one published last year, and attempt to reinvent some aspects. You can see the result for yourself (since this journal is laudably open access, and you will not need a subscription). The article is part of a special issue, arising from a one day symposium held in January 2011 entitled “Visions of a Semantic Molecular Future” in celebration of Peter Murray-Rust’s contributions over that period (go read all 15 articles on that theme in fact!).
On the importance of Digital repositories in Chemistry
Friday, April 3rd, 2009The preceeding blog entries contain stories about chemical behaviour. If you have clicked on the diagrams, you may even have gotten a Jmol view of the relevant molecules popping up. But if you are truly curious, you may even have the urge to acquire the relevant 3D information about the molecule, and play with it yourself. Even after 15 years of the (chemical) Web, this can be distressingly difficult to achieve (or can it be that it is only myself who wishes to view molecules in their native mode?). Thus the standard mechanism is to seek out on journal pages that disarming little entry entitled supporting information and to hope that you might find something useful embedded there. Embedded is the correct description, since the information is often found within the confines of an Acrobat file, and has to be extracted from there. Indeed, that is what I had to resort to in order to write one of the blog entries below. I ground my teeth whilst doing so.

So is there a better way? We think so! The digital repository. If you click on this you should see the entry directly. What can you do there? Well, if you have suitable programs, you can download eg a Checkpoint file of the calculation that created the molecule model and re-activate it there. Or you can download just the CML file for viewing in any CML-compliant program (such as e.g. Jmol). Or you can check up on the InCHi string or the InChI Key of the molecule.