You might have noticed if you have read any of my posts here is that many of them have been accompanied since 2006 by supporting calculations, normally based on density functional theory (DFT) and these calculations are accompanied by a persistent identifier pointer‡ to a data repository publication. I have hitherto not gone into the detail here of the infrastructures required to do this sort of thing, but recently one of the two components has been updated to V2, after being at V1 for some fourteen years[1] and this provides a timely opportunity to describe the system a little more.
The original design was based on what we called a portal to access the high performance computing (HPC) resources available centrally. These are controlled by a commercial package called PBS which provides a command line driven interface to batch queues. Whilst powerful, PBS can also be complex, and for every day routine use it seemed more convenient to package up this interface into a Web-accessed portal which also included the ability to specify the resources needed (such as memory, number of CPUs, etc) to run the desired compute program, in our case the Gaussian 16 package and to complete things by adding a simple interface to a data repository for use when the calculation was completed.
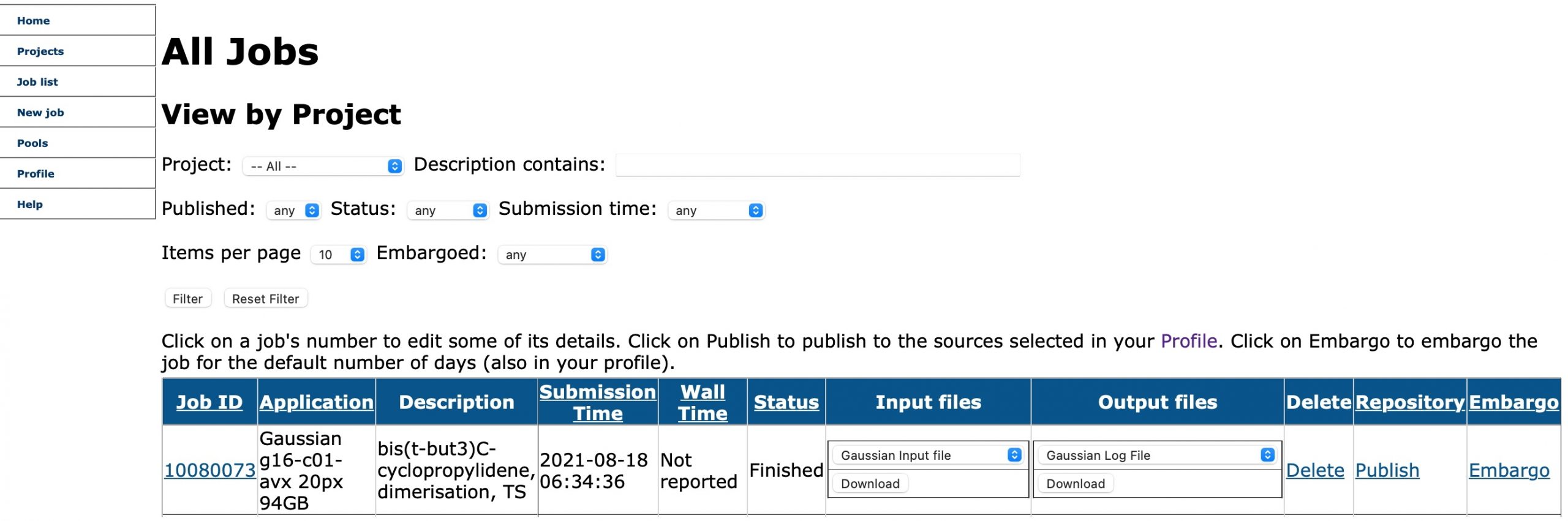
The process of using this tool, which functions in essence as an Electronic Laboratory Notebook or ELN for computational chemistry, can be summarised as a workflow, which occurs horizontally in the screenshot of V1 above. Each job is assigned an internal ID, which is associated with a pre-configured project and given a searchable description. Its status in the PBS-controlled queues is indicated and when finished the associated input and output files become available for download, with an option to delete these if they are not in fact needed, and a final option to publish to the accompanying tool which is a data repository. V1 of this portal was in fact written in the PHP scripting language and controlled behind the scenes using a MySQL database, which allows the entries to be filtered by search terms such as the assigned project or the description. This proved particularly useful when the number of entries reached large numbers (> 100,000 eventually) and meant that even 15-year old entries could be easily found and inspected!
Although this workflow proved highly robust, the underlying PHP system and associated code became increasingly unmaintainable and in 2021 we decided to refactor it for greater sustainability. We had noticed that in 2018, another group had taken the basic concept we had used in 2006, written a more flexible and portable opensource toolkit for building such a portal, calling it Open OnDemand: A Web-based client portal for HPC centers and published a description.[2] In effect, a lot of the work in maintenance is now divested to a separate group and accordingly our software engineering group here at Imperial were far happier using such a tool. So now enter V2 of our own portal, which we now call HPC Access and Metadata Portal or CHAMP.[3]
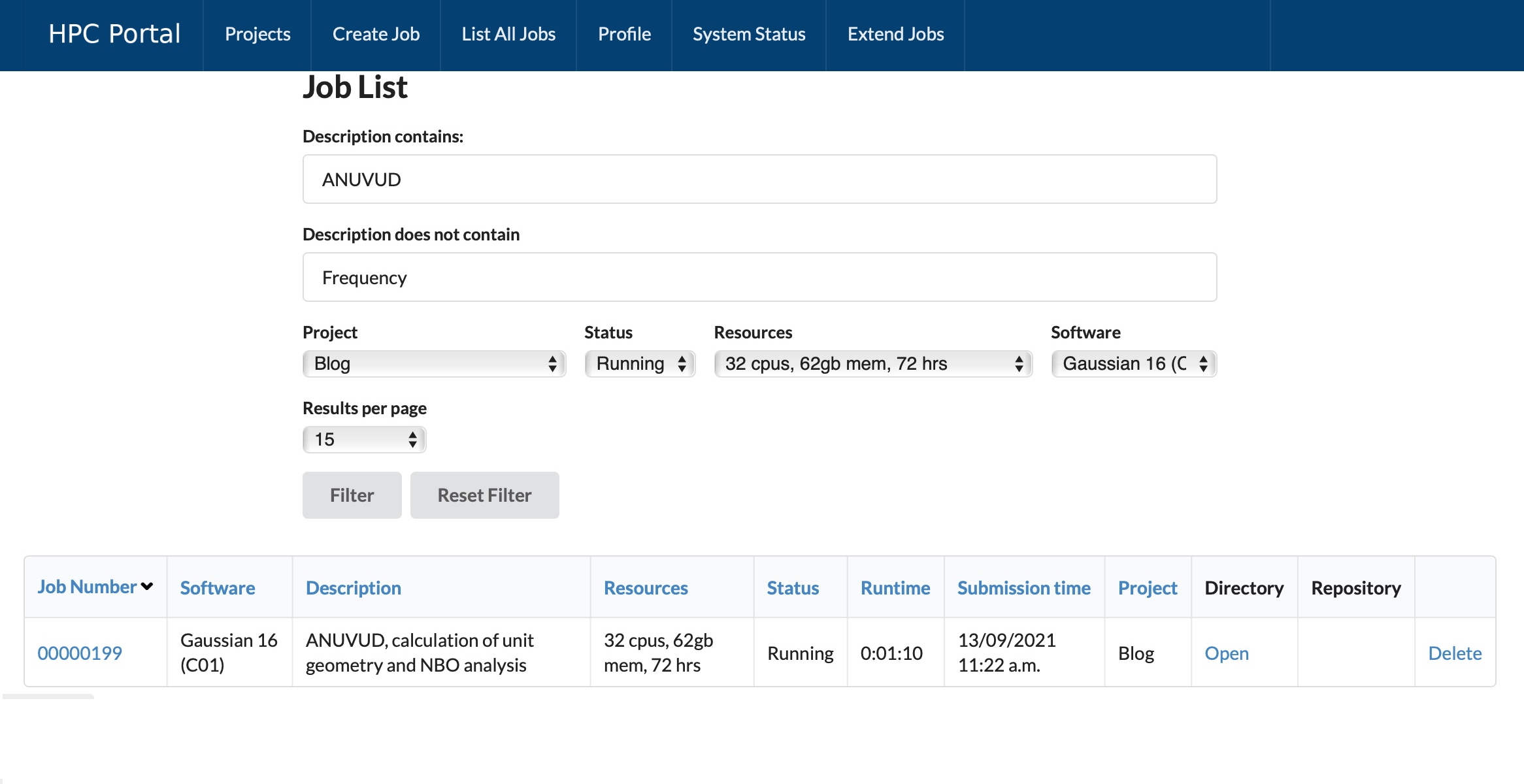
The workflow is very much the same as before, but with added flexibility that allows custom resources to be selected which might include eg special grant-funded priority queues. Additionally, a new directory tool allows inspection of any job inputs or outputs, provided by the Open OnDemand package and which greatly facilitates minute-to-minute management/inspection of jobs to ensure the outputs are those expected for a properly functioning job.
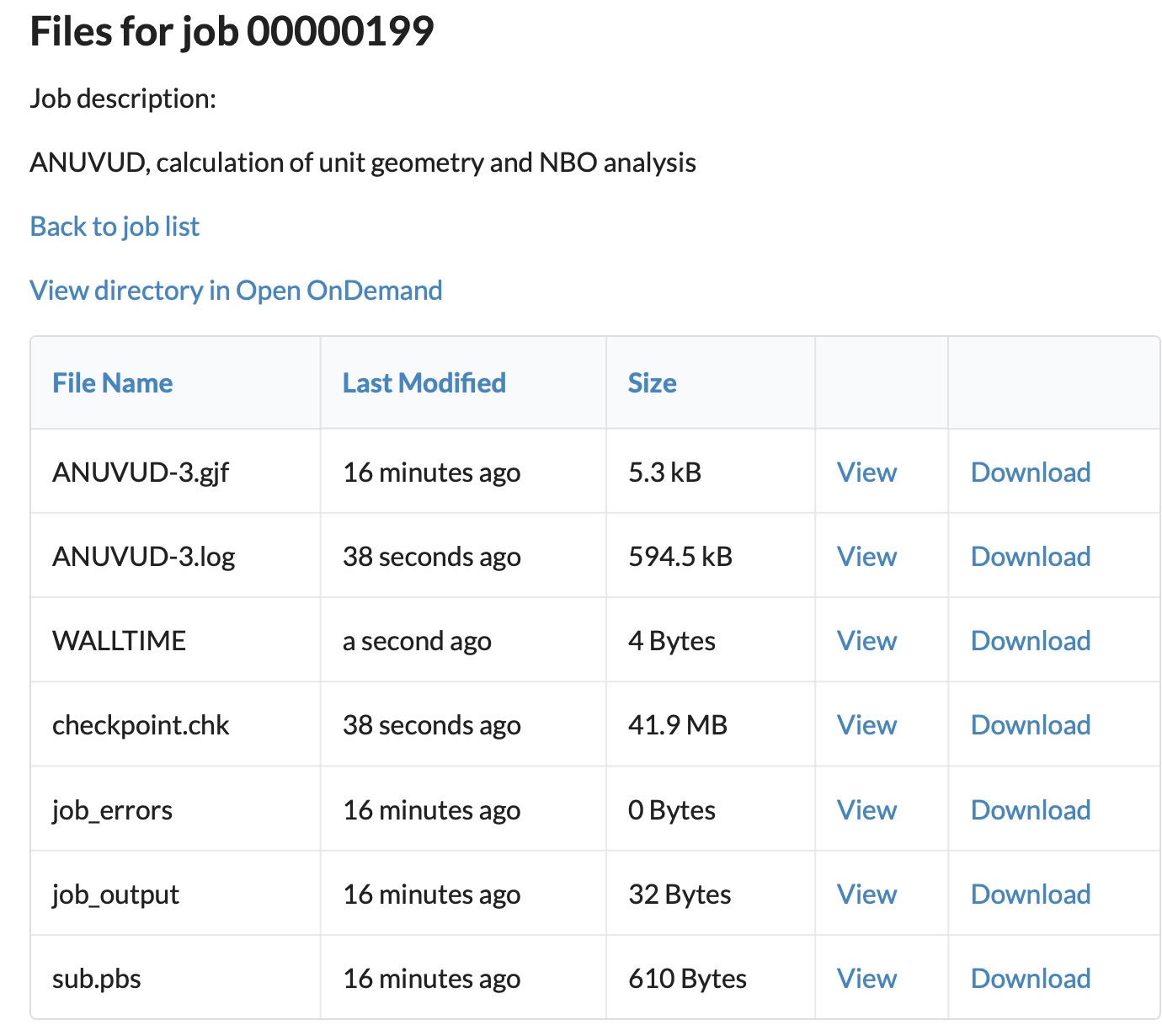
If the job is deemed suitable for sharing, the publish button is pressed. This induces a workflow which, inter alia, converts the system specific checkpoint file to an formatted version which can be used on any system and generates a number of extra files needed for publication of the job.
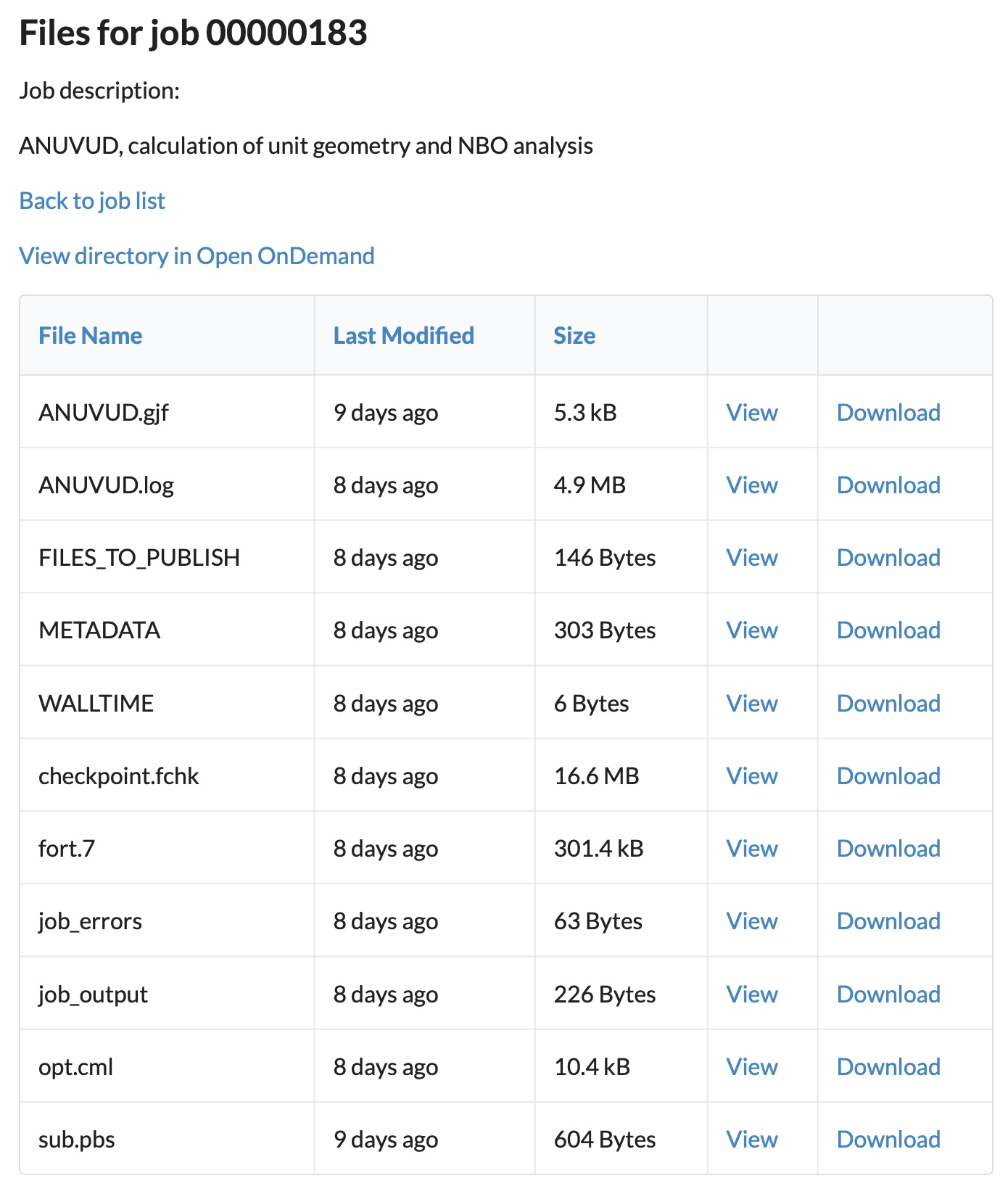
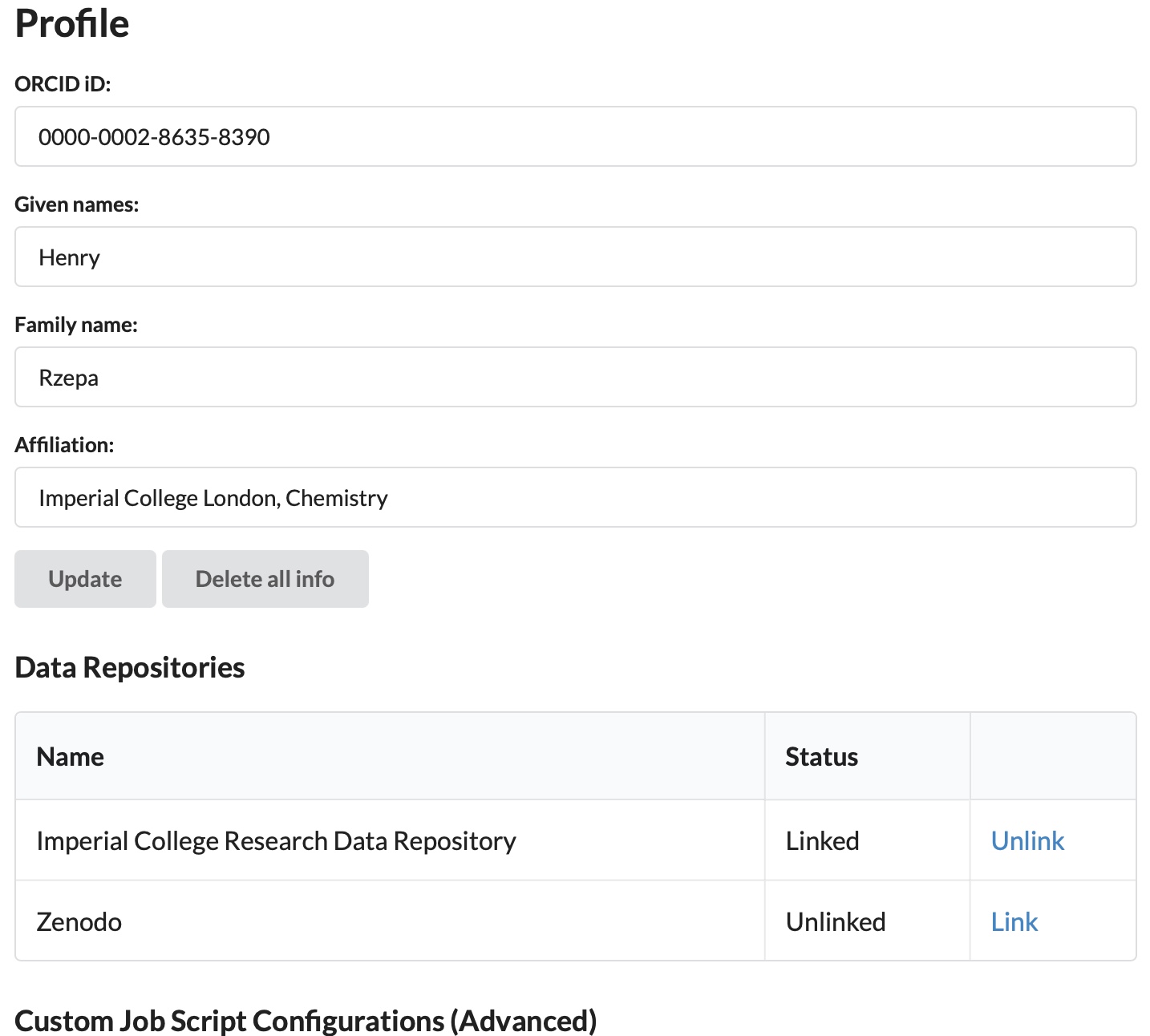
Also of interest is the METADATA file, which generates calculation-specific metadata suitable for injection into the data repository. Currently, this includes the InChI string and Key for the molecule calculated and the Gibbs_Energy, the purpose of which was described in this post. In the future we plan to make this metadata even richer with further information. This calculation-specific metadata will later be conflated with generic metadata for the final publication on the actual repository. That full metadata record includes information about the person who ran the job (their ORCID etc), the institution they are at, the data licensing etc., garnered in part from the profile entry for that user on the CHAMP portal.
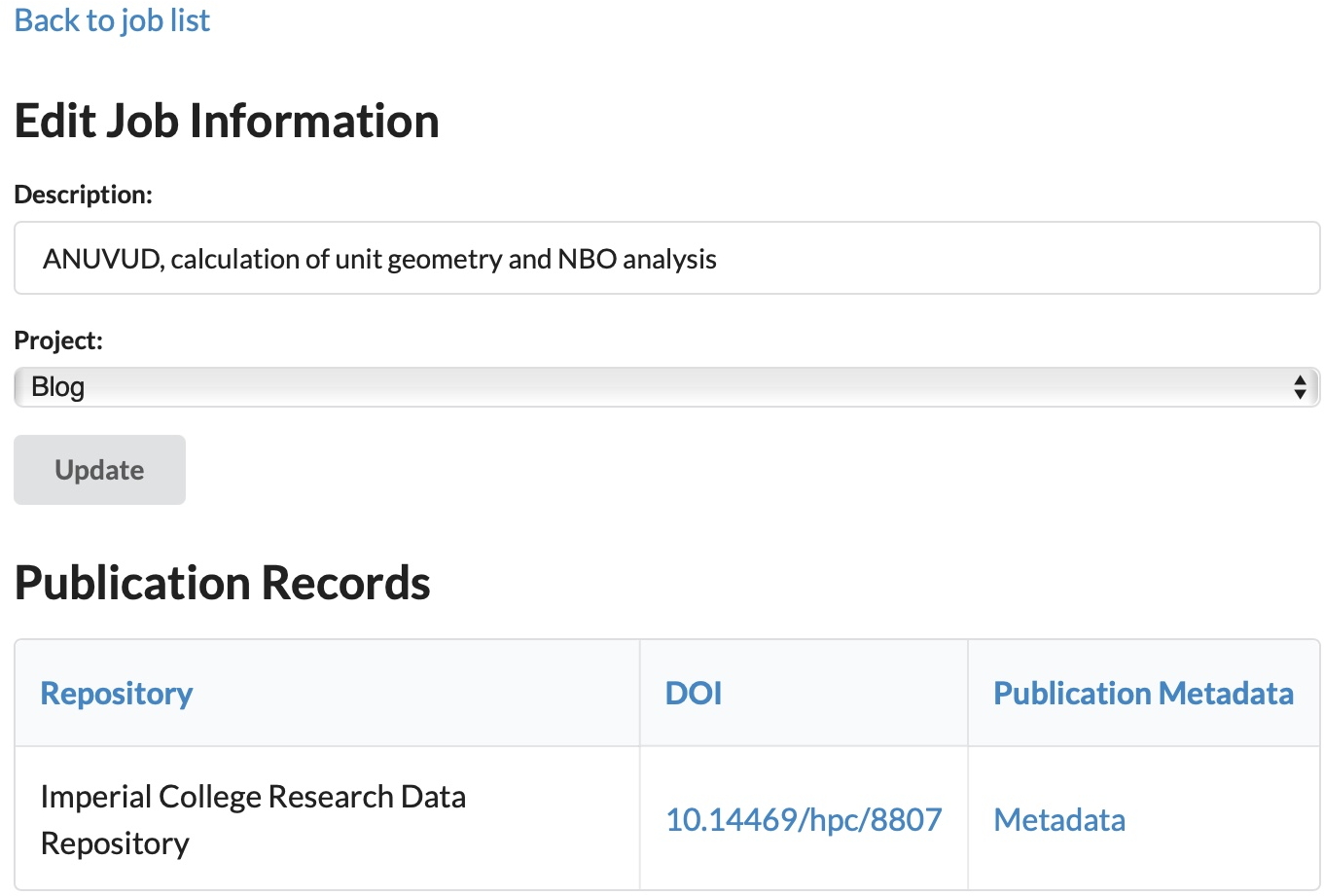
After publication, the CHAMP entry for the job is updated to include the DOI for the data publication, and hyperlinked to allow immediate access to this entry in the repository.
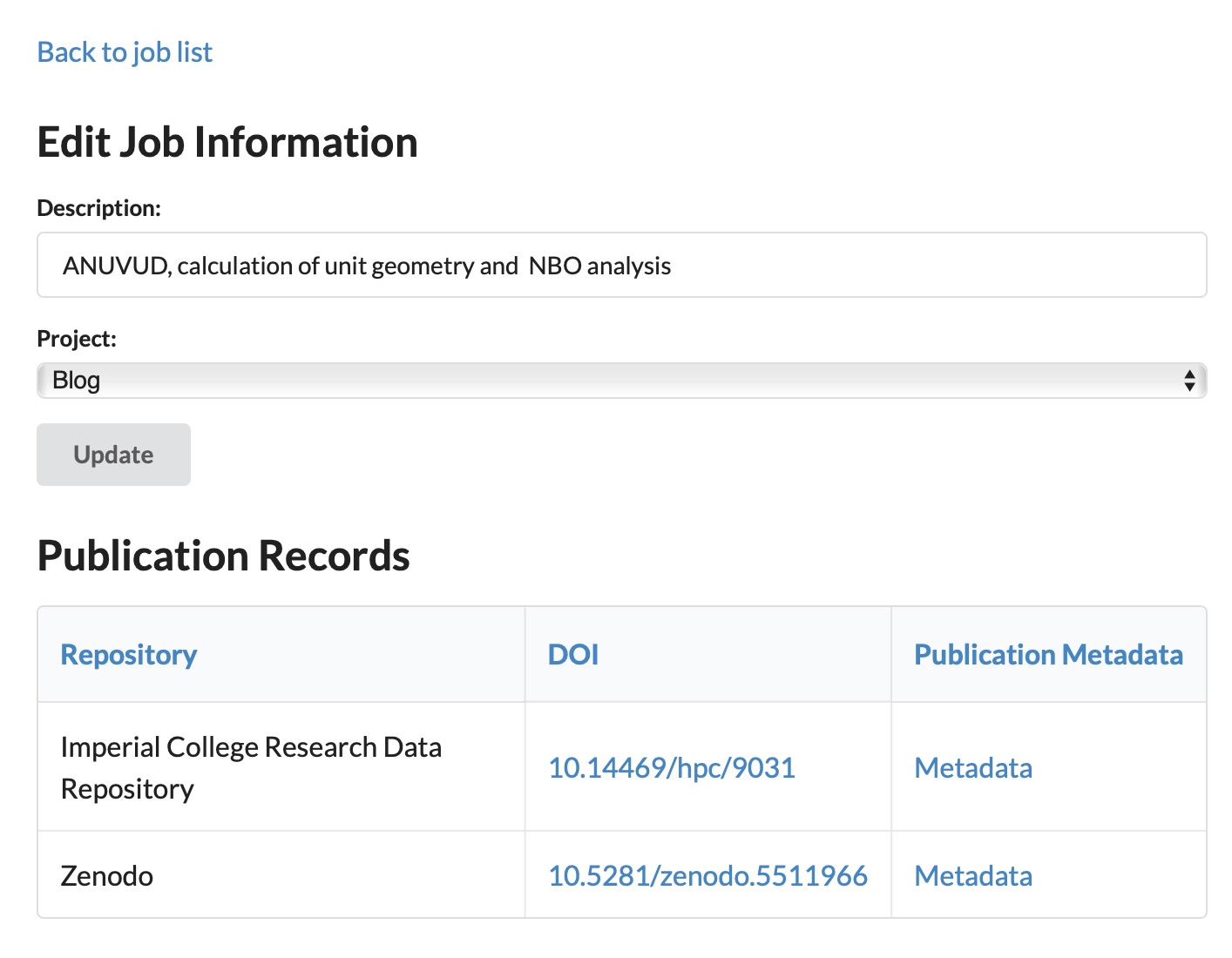
An information page about the job also includes a link to the final full published metadata record(s).
{kind=link}
CHAMP currently includes workflows to publish to the Imperial College repository. Zenodo has also now been added and possibly other repositories in the future as demand requires.
You can see here that I have described how an ELN was originally designed from scratch to control quantum calculations, and how an essential symbiotic partner to this resource was considered to be a data repository at the outset, even way back in 2006. Now, the first of these resources has been refactored into modern form and no doubt the repository end will also be in the future. The code is available for anyone to create a similar compute portal for themselves.
A different version of this description, including more details of the software engineering, will shortly be submitted to the Journal of Open Source Software, along with source code suitable for use with Open OnDemand at https://github.com/ImperialCollegeLondon/hpc_portal/.
‡ Originally in the form of a Handle, which was replaced by the use of a DOI. The DOI for this post itself is 10.14469/hpc/9010
References
- M.J. Harvey, N.J. Mason, and H.S. Rzepa, "Digital Data Repositories in Chemistry and Their Integration with Journals and Electronic Notebooks", Journal of Chemical Information and Modeling, vol. 54, pp. 2627-2635, 2014. http://dx.doi.org/10.1021/ci500302p
- D. Hudak, D. Johnson, A. Chalker, J. Nicklas, E. Franz, T. Dockendorf, and B. McMichael, "Open OnDemand: A web-based client portal for HPC centers", Journal of Open Source Software, vol. 3, pp. 622, 2018. http://dx.doi.org/10.21105/joss.00622
- C. Cave-Ayland, M. Bearpark, C. Romain, and H. Rzepa, "CHAMP is a HPC Access and Metadata Portal", Journal of Open Source Software, vol. 7, pp. 3824, 2022. http://dx.doi.org/10.21105/joss.03824
Tags: Chemical IT