A PID or persistent identifier has been in common use in scientific publishing for around 20 years now. It was introduced as a DOI (Digital Object Identifier), and the digital object in this case was the journal article. From 2000 onwards, DOIs started appearing for most journal articles, journals having obtained them from a registration agency, CrossRef. This is a not-for-profit organisation set up by a publishers association for the purpose. Most readers of journal articles started to use this DOI as an easier way of navigating through invariably different and sometimes confusing metaphors set up by any given journal to navigate through its issues. Readers slowly learnt to prepend the URL http://dx.doi.org/ to the DOI to “resolve” it directly to what is known as the “landing page” of the article. More recently, the prefix recommendation has changed to the slightly shorter https://doi.org/ form. Few readers are aware however that the DOI can serve a much more interesting purpose than just taking you to the article landing page. This post will explore a few of these extras.
- Firstly, a DOI has something called metadata associated with it, and you can view this metadata by prepending a different prefix, such as https://api.crossref.org/works/ to a DOI (as in https://api.crossref.org/works/10.1021/acsomega.8b03005)‡ This returns a “machine response”, since this is very much the audience this version of a resolved DOI is intended for.♥ Alternatively, https://api.crossref.org/works/10.1021/acsomega.8b03005/transform/application/vnd.crossref.unixsd+xml gives a more human-friendly answer. A simple example of why this can be useful can be seen at the end of this blog post.†
- An alternative prefix is https://data.datacite.org/application/vnd.datacite.datacite+xml/ and this brings us to the next big deployment of persistent identifiers, starting around 2010 with the focus now on data. The PID is still called a DOI, but the digital object is now data (or software) rather than a journal article and the agency registering the metadata is now DataCite rather than CrossRef. So e.g. https://data.datacite.org/application/vnd.datacite.datacite+xml/10.14469/hpc/4844 now returns metadata about data. The usefulness of this has in recent times become encapsulated by the expression FAIR data. The metadata can help you Find the data, Access it, how it might be Interoperable and how to Reuse it.
- In 2012 a third prepend of the type https://orcid.org/ was introduced to provide metadata about researchers, as in https://orcid.org/0000-0002-8635-8390
- Then in 2019, the growing ecosystem expanded to organisations, as with the new resolver https://ror.org/ and with PID e.g. 041kmwe10, hence https://ror.org/041kmwe10
After this long introduction, its time to turn to the latest proposed PID type. As the title suggests, it is for instrumentation and it is introduced at https://doi.org/10.5438/tdk2-2g94 (and yes, metadata at https://data.datacite.org/application/vnd.datacite.datacite+xml/10.5438/tdk2-2g94). An example describing the properties of an instrument♣ can be found at DOI: 10.7914/SN/SH and in the chemistry community we can already start asking ourselves questions such as what types of instrument deserve their own PID, and what sort of information about the instrument might be usefully associated with the data and be of interest to other researchers.
This is early days yet for this latest proposal, but already one can start to see how this ecosystem might be operating in the future. Consider the scenario. A research team at a specified institute (PID) consisting of say four individuals (PID for each) uses a recently funded (PID) NMR spectrometer (PID) fitted with an special ultra-sensitive low temperature probe (PID), record a collection of individual solution spectra and then publish both the collection and the raw data from which the spectra are derived, each with their own PID. With the help of quantum simulations (PID) of the spectra, they interpret the molecular structures and confirm this with a crystal structure (PID). A student graduates with a PhD based on this work (PID). Finally they publish their story (PID) in a journal that releases open citations (PID), thank their instrument funders (PID) and perhaps blog about it (PID♠). Since machines can access the metadata records of all these PIDs, the entire endeavour becomes linked with exchanged information. Starting at any single PID, one should easily be able to trace all the others and locate the data and other information associated with all the aspects of the project.
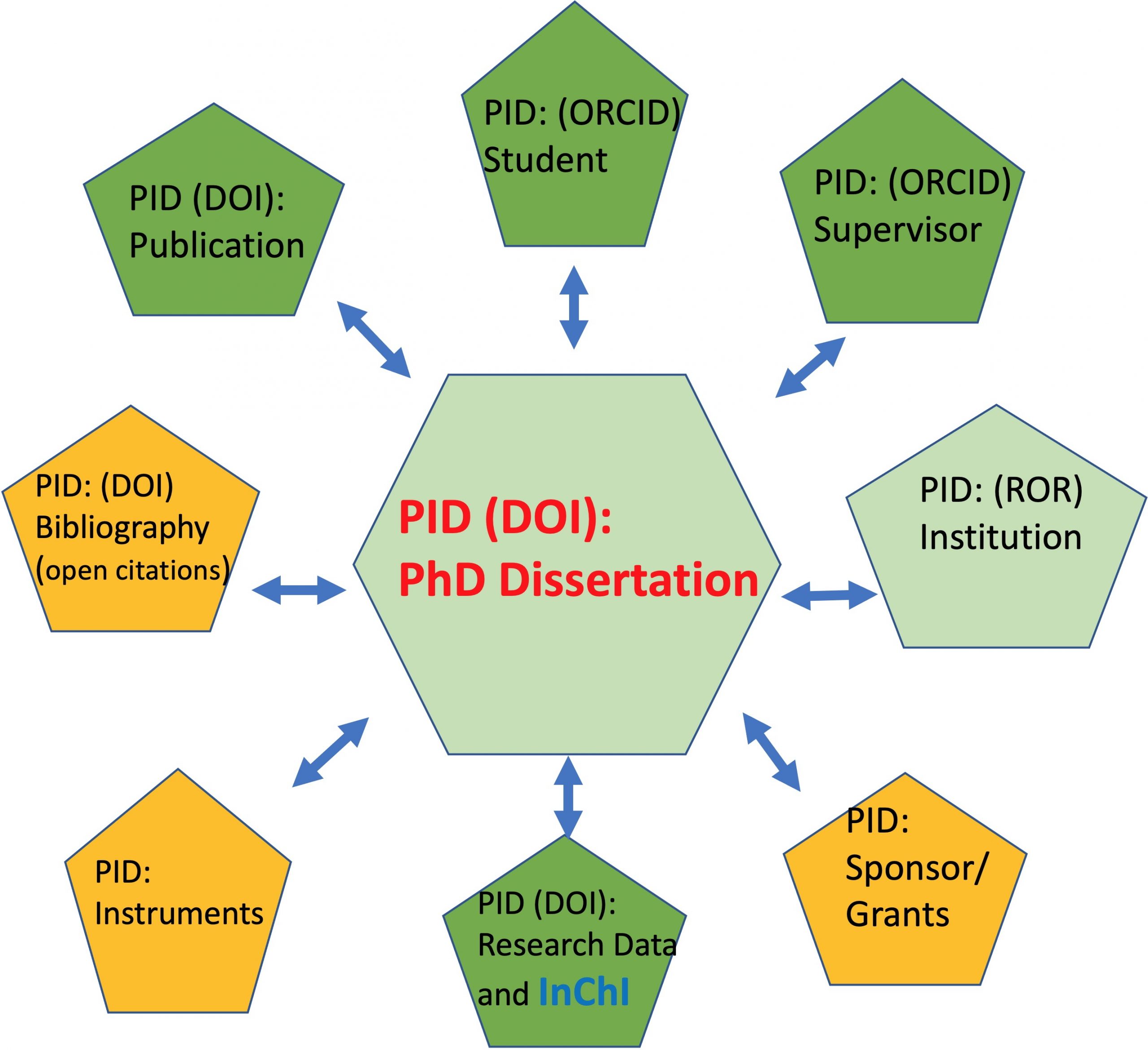
I used the term future above, but in fact much of the above infrastructure is already operating, albeit in early days mode. So this is one to keep an eye out for; things might happen more quickly than you might think!
‡ Documented at eg https://github.com/CrossRef/rest-api-doc#queries ♥If you want a more human readable version, use this JSON to XML converter †This is how the citations at the end of this post are generated. In the post itself they are inserted using e.g. ⌈cite⌉10.1021/acsomega.8b03005⌈/cite⌉ and a plug-in then expands this to a query of the above resource and formats the response to generate the bibliographic details at the end.[1] ♣Documentation for how to implement this is found at https://github.com/rdawg-pidinst/schema/blob/master/schema.rst and before you ask, no this one does NOT have a PID! ♠This blog post has PID: 10.14469/hpc/7016
References
- A. Barba, S. Dominguez, C. Cobas, D.P. Martinsen, C. Romain, H.S. Rzepa, and F. Seoane, "Workflows Allowing Creation of Journal Article Supporting Information and Findable, Accessible, Interoperable, and Reusable (FAIR)-Enabled Publication of Spectroscopic Data", ACS Omega, vol. 4, pp. 3280-3286, 2019. http://dx.doi.org/10.1021/acsomega.8b03005
Tags: Chemical IT